TCP BBR
TCP is an end-to-end protocol that guarantees we can have reliable communication channel over an unreliable network. When we send data from one node to another, network bandwidth can be congested, packets can be dropped by network device, buffer of receiver sides can be overloaded. In order to overcome those situations, TCP always in development. Now let’s talk about the control mechanisms of TCP and indicate the importance of new algorithm named as TCP BBR at the last section.
TCP Flow Control:
It is the method to ensure that excessive traffic which is more than receiver can handle is not sent . So, as a sender, we need to know how much free space is available on the receiver. Otherwise, if we send data to receiver so fastly, there will be packet drop.
How Applications communicate each other? Sender application puts the data which needs to send in sender buffer. After data is sent via link, it is stored in receive buffer before sending to application level. When the receiver application read the data from its buffer, then the receive buffer become available for the new packets.

Every time TCP gets a packet , it sends a TCP ACK message to the sender to inform that it received the packet succesfully. Within this ACK packet, there is value which states the current receive window(rwnd) size.[1]

TCP Sliding Window
TCP uses sliding window to control the number of packets sent but not acknowledged yet. I will try to explain sliding windows as simple as possible with the example below.
Let’s say that Application X has 10000 bytes to be sent. Since the MTU is set to 1000bytes, TCP stack divides data into 10 packets, each 1000bytes. Application Y reported its rwnd size as 5000bytes. With that information, X sends 5 packets. After a short time, X received a ACK message for the first 2 packets and the rwnd size is still 5000bytes. While 3 packets are in flight, X sends 2 packets more.
If for some reason, the application Y reports its rwnd size smaller than the previous one, X would adapt the new situation and decrease the number of packets to be sent.
To sum up with one sentence;
Slow sender speedy receiver — No Flow Control,
Fast sender, slow receiver — Flow control is required.
TCP Congestion Control
With flow control, the receiver dictated how much data can be send by sender. Now, there is another entity we need to take into account. It is network itself. If the network can not transfer data as fast as the sender created, it must inform the sender to slow down. Please be aware that TCP congestion control is about preventing the sender from overwhelming the network.
It consists of 3 phases. Before explaining the phases we need to know some terms;
- RTT: time difference between the TCP segment and its ACK. RTT measurement is done constantly during the TCP connection.
- MSS(Maximum-Segment Size):Maximum payload size a receiver accept in single packet.
- CWND(Congestion Window): Variable that limits the amount of data the TCP can send into the network before receiving an ACK.
- ssthresh: Slow start threshold. At first, its size is equal to window size.
Lets talk about the phases:
- Slow Start Phase: Initially, cwnd =1MSS. Since increase of speed depends on RTT value, in general, cwnd increments exponentially in that phase till the ssthresh limit.
- Congestion Avoidance Phase:After reaching the sshtresh, cwnd increments by 1MSS. So, cwnd=cwnd+1.
- Congestion Detection Phase: This phase is the one at which senders detects the packet loss. How senders understand there is packet loss. There is two ways to understand it. First, sender waits RTO timer(retransmission timeout) until it gets an ACK for the packet sent. If it does not get an ACK, it thinks there is a packet drop and retransmit the packet. The other way of understanding packet loss is that if sender gets 3 DUP-ACK message which is named as Fast Retransmission.
With the detection of packet loss, ssthresh value is reduced to the one half of window size.
TCP BBR:
There are many TCP congestion control algorithms such as RENO,CUBIC that are loss-based ones, they will reduce their sending rates in response to packet loss. They are reactive since they wait until loss is observed before taking an action to fix the loss.
As for TCP BBR, Bottleneck Bandwidth and Round-trip propagation time (BBR) is a TCP congestion control algorithm developed at Google in 2016. Google, Dropbox ,Spotify has also been using BBR.
BBR is Measure-based protocols track the change in the network conditions and take predefined actions based on these measures. TCP BBR works by measuring the RTT and throughput, and uses these to calculate the BDP(Bandwidth Delay Product). Using the calculated BDP, BBR attempts to operate with around 1 to 2 BDP of packets in flight, and thus operate near the optimal. [2]
The throughput improvements are especially noticeable on long haul paths such as Transatlantic file transfers, especially when there’s minor packet loss.With the loss-based algorithms, it will not be possible to use the links efficiently, and they also cause a Bufferbloat which cause too much buffering and latency.
Since BBR attempts not to fill the buffers and not effected by packet loss as much loss-based ones, it tends to be better in avoiding buffer bloat. [3]
Now, let’s see the real effects of BBR in my LAB environment.
I used two ubuntu server whose kernel versions are as below. The kernel version should be 4.9 or above.

Then I added following lines to “/etc/sysctl.conf” file by using “vi” editor. It is needed to enable BBR on server.
net.core.default_qdisc=fq
net.ipv4.tcp_congestion_control=bbr
The server is rebooted for the changes to take effect.
One of the commands below you can easily change TCP congestion algorithm used.
sysctl -w net.ipv4.tcp_congestion_control=bbr
sysctl -w net.ipv4.tcp_congestion_control=cubic
sysctl -w net.ipv4.tcp_congestion_control=reno
You can also use the command below to see your algorithm.
$ sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = bbr
I have used Linux Traffic Control(tc) utility to emulate the latency and packet loss values. With that command below,
We added just 50ms latency. I tested the effect of it with ping.
zafer@ubuntu:~$ sudo tc qdisc replace dev ens33 root netem latency 50ms
See the ping times;
zafer@ubuntu:~$ ping 192.168.110.130
PING 192.168.110.130 (192.168.110.130) 56(84) bytes of data.
64 bytes from 192.168.110.130: icmp_seq=1 ttl=64 time=50.4 ms
64 bytes from 192.168.110.130: icmp_seq=2 ttl=64 time=50.3 ms
I set the algorithm to cubic since it is the most common used one recently. Please note that we are doing all this on sender side.
I tried to use iperf3 to test those scenarios, unfortunately, it does not realize that packet losses and latency changed by tc. That’s why I used scp from one to another.
The effect of latency;
Let’s see the result for cubic with 0% packet loss and 10ms latency. It takes 5 seconds to transfer file whose size is 200MB.

Under the same situations and this time algorithm is BBR.

The result is almost same for BBR and Cubic without any packet loss.
The effect of Packet loss;
I will repeat the same test above adding just minor amount of packet loss.
With the command below I am adding 1% packet loss , and latency is 50ms.
zafer@ubuntu:~$ sudo tc qdisc replace dev ens33 root netem loss 1% latency 50ms
When Cubic enabled

When BBR enabled

Please check the graphs below to see the bandwidth usage to see the difference.
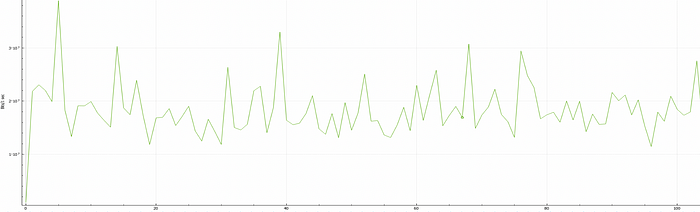
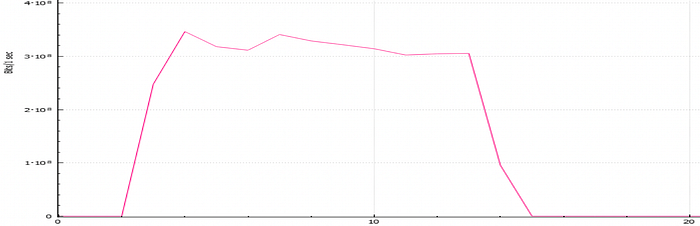
The tests above show the effect of packet loss and latency on TCP throughput. The impact of 1% of packet loss on path is really surprised me. As I stated above, BBR is not so affected by packet loss like cubic or reno. Because traditional algorithms relies on packet loss, and when they see any packet loss they are changing the cwnd size immediately.
Before finishing the article, I need to state few things in my mind.
-TCP congestion control algorithm is enabled on the sender side only. The clients does not need to be aware of BBR.
- While doing those tests, I thought that with one command you are getting the all bandwidth and pushing out other TCP streams which are using another TCP algorithms. As far as I read, with BBRv2 this kind of situations will be solved.
References:
[1] https://www.brianstorti.com/tcp-flow-control/
[2] https://digitalcommons.wpi.edu/cgi/viewcontent.cgi?article=7727&context=mqp-all
[3] https://medium.com/@atoonk/tcp-bbr-exploring-tcp-congestion-control-84c9c11dc3a9
